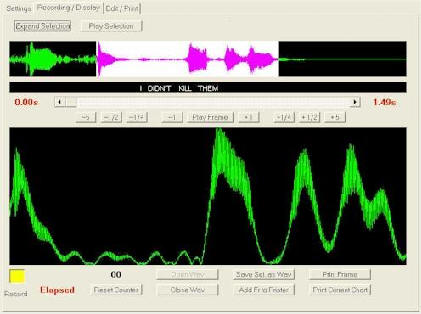
| Voice stress analysis | ||||||||||||
| Voice Stress Analysis (VSA) is technique that uses inaudible voice
cues to detect stress, with the aim of producing a lie detection system. VSA
is newer than the "classic" lie detector, the polygraph, yet it is just as
controversial. Diogenes Digital Voice Stress Analysis application, was originally used in determining attempts at deception in law enforcement activities. In the world today you may hear the words "lie detector" in reference to this type of technology, but this type of technology actually detects deception in the human voice. Subsequently it's advanced user friendly capabilities found additional applications in deception determination in arson, counter narcotics, insurance fraud, employment screening, private investigation, anti-terrorism, interrogation, covert counter intelligence and the like. Many agencies are currently utilizing our instrument for pre-employment examinations instead of old outdated polygraph machines.
VSA records an inaudible component of human voice, commonly referred to as the Lippold Tremor. This is often claimed by the companies selling these kinds of products. However, Lippold's article is concerned with tremor in one particular finger and mentions nothing whatsoever in connection to lie or stress detection. When the flight or fight response is triggered, one of the many effects it causes is an involuntary tensing of the 'soft' striated muscles, particularly, the laryngeal muscles, they claim. Under normal circumstances, the laryngeal muscle is relaxed, producing a Tremor in the voice at approximately 12 Hz. Under stress however, the tensed laryngeal muscle lowers the frequency of the Tremor, he higher the stress, the lower the Tremor's frequency. VSA technology records psycho-physiological stress responses that present in human voice, when a person suffers psychological stress in response to a stimulus (question) and where the consequences of lying may be dire for the subject being 'tested'. In the "Detection Of Deception" (DOD) scenario, the voice-stress produced in response to a relevant question (did you do it?) is referred to as deceptive stress. The technique's accuracy remains debated by polygraph-industry initiated research. There are independent research studies that support the use of VSA as a reliable lie detection technology, whilst there are other studies that dispute it's reliability. The skill and experience of the VSA examiner is of utmost importance. However, the question is not about the reliability of the methods, but the validity. No research has ever shown any kind measurable tremor in the voice and no research has ever connected the non-existent tremor to stress detection... VSA is distinctly different to Layered Voice Analysis (LVA) LVA is used to measure different components of voice, such as pitch and tone. LVA is available in the form of hand-held devices and software. LVA produces readings such as 'love', excitement, fear; which are not useful in DOD applications.
However (again) if one reads the patent papers on LVA (freely available) one soon discovers that LVA is based on trivial Visual Basics coding written by someone who knows nothing about voice analysis. It simply measures patterns in the sampling artifacts of a signal and makes some simple statistics on those patterns and then draws idiotic conclusions similar to the ones you will find in horoscopes. Conclusion, a door slamming might lie, however slam it again and it might tell the truth! ApplicationsThe purpose of a VSA examination is to determine the truthfulness of responses made by an examinee regarding the subject under investigation. Determinations are made by analyzing and scoring the voice-grams produced by the examinee. Traditional analysis of voice grams was achieved by allocating "percentages of stress" ( % ) according to the patterns so produced. High levels of (deceptive) stress indicate that the examinee is deceptive as is the case with polygraph. In respect of VSA, squared voice grams indicates higher stress, whilst 'wave form' or 'domed' signatures indicate less stress. Questions may be posed to elicit simple "yes" or "no" answers, but can be posed to produce a narrative response. Questions are formulated for each individual being examined to compare situational stress signatures with Control Question and Relevant Question signatures, in order to identify (deceptive) 'stress signatures'. VSA technology together with validated testing protocols, is designed to protect the innocent and avoid 'false positive' results. VSA is designed to assist any investigation by establishing the veracity of a subject's verbal responses. Devices used to analyze voice stress are usually used in the presence of the individual under investigation; however, they can also be used without his or her knowledge. Since all that is needed is a voice, a wireless microphone, a telephone connection, or even a tape recording can provide the necessary input signal. Traditional VSA differs from LVA as follows: VSA utilities the McQuiston-Ford algorithm and this is the technology developed in the USA for the US Defence Agencies and is used by US Law Enforcement agencies. There are no known physical countermeasures for VSA. Conversely, the simple use of a 'tack' placed under the tongue of the examinee, to be used as a countermeasure, can reduce the accuracy of polygraph results from 98% to 26%. (Ref: Honts 1993) Methodology & AccuracyThe McQuiston-Ford algorithm used for Voice Stress Analysis is reliably accurate. The recorded "micro tremors" in a persons voice are converted via the algorithm into a scorable voice gram. The discrepancy in researched accuracy may result from incorrectly trained or non-trained persons utilizing the technology incorrectly. This is evident by some Polygraphists trying to "test" VSA technology without having received accredited training in the use thereof. Most 'polygraph only' associations have disputed the accuracy of VSA, although many accredited polygraphists have trained in the use of VSA and use VSA to good effect. The traditional analysis and scoring of voice-grams by means of assigning 'percentages' is clumsy and unreliable. In 2005, Clifton Coetzee (Polygraph & VSA Instructor) devised a scoring method for voice grams incorporating the 'UTAH 7 Point' scoring system, as used by modern day polygraphists. Reactive or Responsive patterns are assigned a weighting of +3 to -3. The use of CQT testing protocols developed by John Reid and Cleve Backster are used for greater reliability of VSA results. It is important that VSA examiners be skilled in the use of enforced, timed pauses between stimulus (question) and response (answer). As in the polygraph situation, the Flight or Fight syndrome has an onset delay, which must be considered by examiners to achieve reliable results. The American Polygraph Association's website lists conclusions from multiple "university-grade studies" into the accuracy of voice stress analysis as a means of detecting the subject's truthfulness [1]. All cast doubt on the validity of the results of such tests; many describe the results as no better than chance. The term "university-grade" is itself meaningless. While several articles come from peer reviewed journals, many others are research reports to or by government agencies which generally have no peer-review process. It should be noted that prior to an APA Annual Convention in 2000, many APA Polygraph Instructors were teaching VSA alongside polygraph. It might be that the huge success of VSA was perceived as a threat to the polygraph industry, which incidentally is a source of funding to the APA ReferencesSource: www.diogenescompany.com and www.wikipedia.org
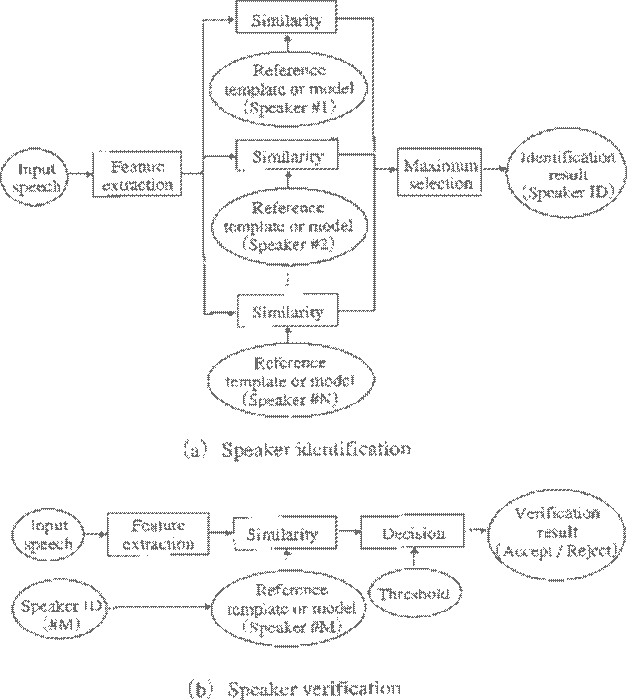
SPEAKER RECOGNITION: (By Ms. Satovisha Bhattacharya, Amity University) Speaker recognition, which can be classified into identification and verification, is the process of automatically recognizing who is speaking on the basis of individual information included in speech waves. This technique makes it possible to use the speaker's voice to verify their identity and control access to services such as voice dialing, banking by telephone, telephone shopping, database access services, information services, voice mail, security control for confidential information areas, and remote access to computers. There is a difference between speaker recognition (recognizing who is speaking) and speech recognition (recognizing what is being said). Generally these two terms are frequently confused and voice recognition is used as a synonym for speech recognition instead.
Variants of speaker recognition Each speaker recognition system has two phases: Enrollment and test. During enrollment the speaker's voice is recorded and typically a number of features are derived to form a voice print, template, or model. In the test phase (also called verification or identification phase) the speaker's voice is matched to the templates or models. Speaker recognition systems employ three styles of spoken input: text-dependent, text-prompted and text-independent. This relates to the spoken text used during enrollment versus test. If the text must be the same for enrollment and test this is called text-dependent recognition. It can be divided further into two cases: The highest accuracies can be achieved if the text to be spoken is fixed. This has the advantage that the system designer can devise a text which emphasizes speaker differences. However, since the text is always the same such systems are vulnerable to impostors. Furthermore, it is not very user friendly if all users have to remember some complex text and in addition it makes the system language dependent. Another type of text-dependent system uses pass phrases. The user is free to pick a phrase during enrollment but must use the same phrase during test. Most speaker verification applications use this type of text-dependent input. It has the advantage that an impostor must know the pass phrase, which adds a level of security. In text-prompted systems the speaker is asked to speak a prompted text. In principle this could be any kind of text. This however complicates the recognition process quite a bit. On the one hand the system knows the text that is being spoken. On the other hand the system must somehow know how this randomly selected text should sound if spoken by a particular speaker.
Speaker Recognition is classified into two:- 1. SPEAKER IDENTIFICATION- It is the task of determining an unknown speaker's identity. It is a 1:N match where the voice is matched to N templates. Speaker identification systems are more likely to operate covertly without the user's knowledge. This can for example be used to route users to the correct mailbox, identify talkers in a discussion, alert speech recognition systems of speaker changes, check if a user is already enrolled in a system, etc. 2. SPEAKER VERIFICATION- If the speaker claims to be of a certain identity and the voice is used to verify this claim this is called speaker verification or tape authentication. Speaker verification is a 1:1 match where one speaker's voice is matched to one template (and possibly a general world template).
ANATOMY OF SOUND PRODUCTION Speaking involves a voice mechanism that is composed of three subsystems. Each subsystem is composed of different parts of the body and has specific roles in voice production. Three Voice Subsystems
Key Function of the Voice Box The key function of the voice box is to open and close the glottis (the space between the two vocal folds).
Key Components of the Voice Box
 SPEECH SIGNAL PROCESSING Speech signal processing refers to the acquisition, manipulation, storage, transfer and output of human utterances by a computer. The main goals are the recognition, synthesis and compression of human speech:
PATTERN RECOGNITION It is the act of taking in raw data and taking an action based on the category of data. In the case of speech recognition, the pattern recognition systems take in the digital conversions of sound using a sensor, then a feature extraction mechanism computes numeric or symbolic information from the observations and later a classification scheme does the actual job of classifying the observations. ACOUSTIC CHARACERISTICS OF SPEECH SIGNALS Acoustics is the branch of physics that deals with the study of sound. The acoustic characteristics of sound signals include: · Pitch- It is the perceived fundamental frequency of a sound. Pitch is directly proportional to frequency. High frequency=High pitch · Loudness- It is the quality of sound that is psychological correlate of intensity. It also depends on frequency. High frequency= Less loudness More intensity= More loudness More amplitude= More loudness
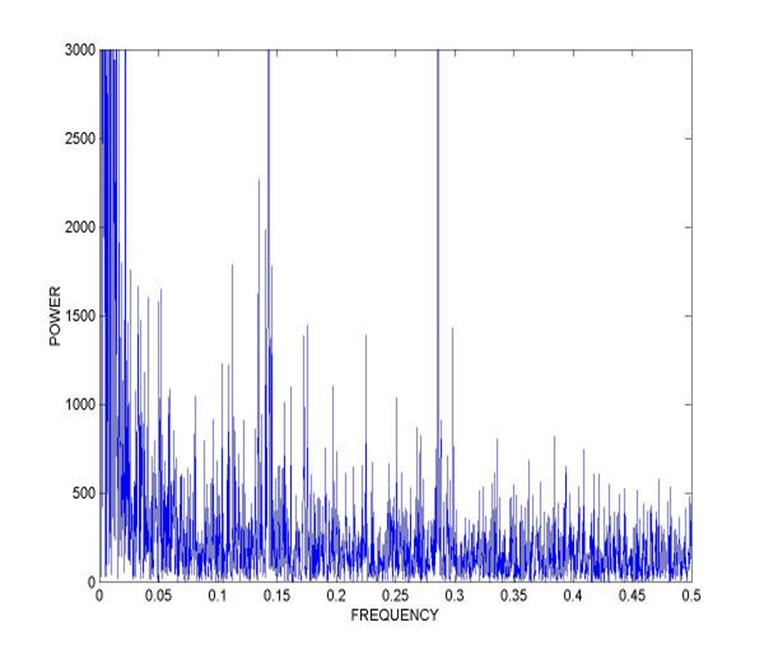
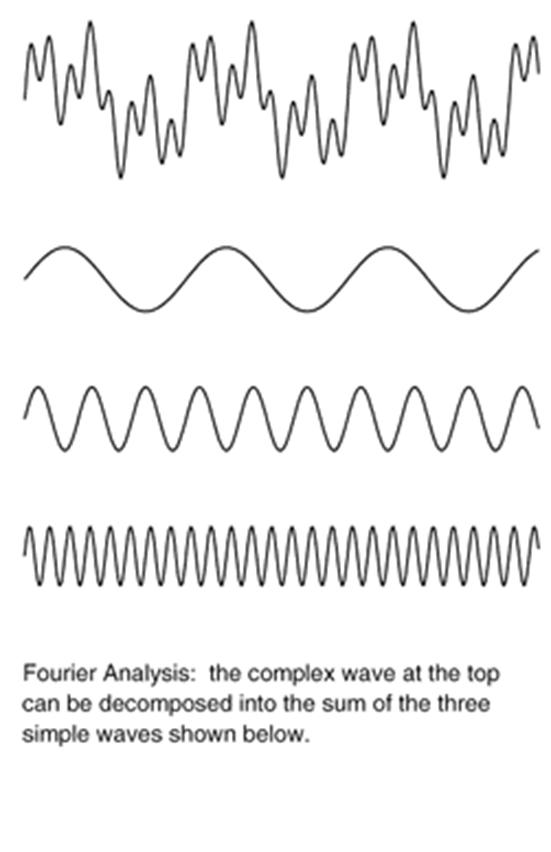
FOURIER ANALYSIS Fourier analysis, named after Joseph Fourier's introduction of the Fourier series, is the decomposition of a function in terms of a sum of sinusoidal basis functions (vs. their frequencies) that can be recombined to obtain the original function. That process of recombining the sinusoidal basis functions is also called Fourier synthesis (in which case Fourier analysis refers specifically to the decomposition process). In terms of signal processing, the transform takes a time series representation of a signal function and maps it into a frequency spectrum, where ω is angular frequency. That is, it takes a function in the time domain into the frequency domain; it is a decomposition of a function into harmonics of different frequencies. Applications in signal processingIn signal processing, Fourier transformation can isolate individual components of a complex signal, concentrating them for easier detection and/or removal.
Analog-to-digital conversion is an electronic process in which a continuously variable (analog) signal is changed, without altering its essential content, into a multi-level (digital) signal. The input to an analog-to-digital converter (ADC) consists of a voltage that varies among a theoretically infinite number of values. Examples are sine waves, the waveforms representing human speech, and the signals from a conventional television camera. The output of the ADC, in contrast, has defined levels or states. The number of states is almost always a power of two -- that is, 2, 4, 8, 16, etc. The simplest digital signals have only two states, and are called binary. All whole numbers can be represented in binary form as strings of ones and zeros. This is achieved by the process of Quantization that breaks the continuous sound signals into small quantas and represents it in the form of digital signals that are understandable by the computer.
Quantized signal
These signals can be represented in the form of digits as well by the process of digitization.
SOUND SPECTROGRAPH
ANALYSIS OF AUDIO-VISUAL SIGNALS FOR AUTHENTICITY Thus, we observe that the principles of sound recognition can be used for the analysis of audio-visual signals for establishing their authenticity. The sound produced by the vocal organs is obtained and then it is subjected to fourier analysis where it is broken down into its constituents and the background noise can be removed. The individual waves thus obtained are subjected to quantization when the waves or analogue signals are broken down into small quantas and later into digits by digitization which can be read by a computer. At this stage when the data is in the computer in a digital form, a sound spectrograph can be obtained that depicts the individual characteristics of the wave which can be analysed or compared. Also in this procedure a wide variety of software can be used. For example, a software cuts the sound files at the required places into segments and then recombines the desired segments or a software that converts sound waves into text etc. CASE STUDIES 1. Excerpt from The Tribune, Chandigarh The Central Forensic Sciences Laboratory (CFSL) Chandigarh played crucial role in providing conclusive evidence in this case. CFSL experts proved in the court through a computer analysis that the voice tape recorded by the Delhi police while intercepting a telephone call matched that of Geelani. The Delhi police had intercepted phone calls on the basis of telephone numbers decoded from the mobile SIM cards seized from the terrorists killed during the attack. The conversation between Geelani and the caller was in Kashmiri. The question before the prosecution was how to prove that the intercepted voice was of Geelani’s. First samples of Geelani’s voice and of the one intercepted were sent to CSFL experts in Delhi. But they could not establish any link because of a high level of background noise in the tape and lack of technology required for micro acoustic analysis of the speaker. Then the tape and a sample of the Geelani’s voice were sent to CFSL Chandigarh, which succeeded in their auditory analysis and later presented the same in court.
REFERENCES: 1. Internet Resources; 2. Sharma, B. R., Forensic Science in Criminal Investigation and Trials Fourth Edition with supplement, pp 241-256. (By Ms. Satovisha Bhattacharya, Amity University) |
||||||||||||
| © 2008 : SANTOSH RAUT. www.santoshraut.com Delight Data System & Server |